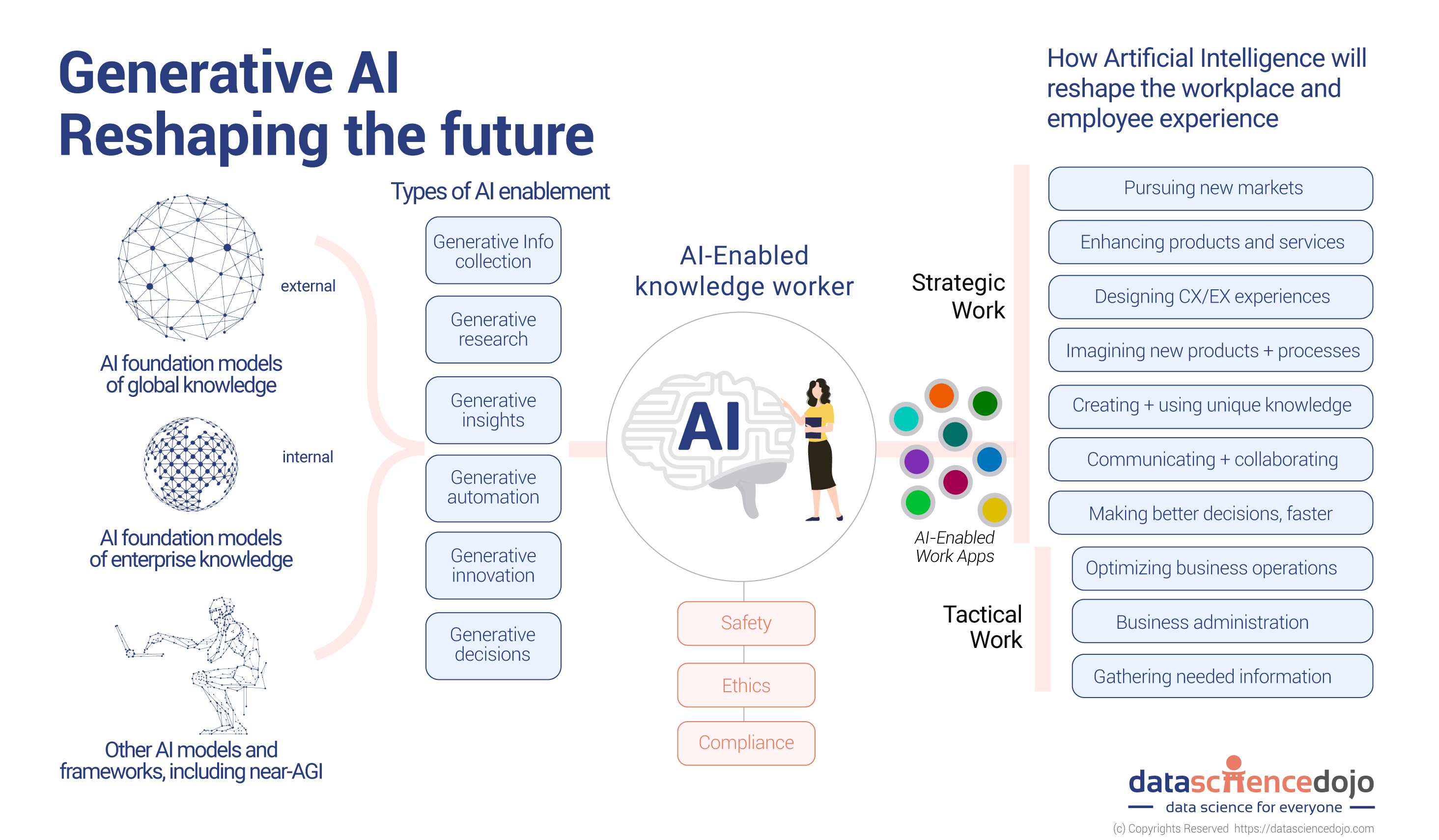
In recent years, the importance of synthetic data has surged, particularly in the realm of machine learning and artificial intelligence. With the growing necessity to train models effectively and efficiently, quality-diversity generative sampling has emerged as a powerful tool. This approach not only enriches the training datasets but also enhances the performance and adaptability of AI systems. By leveraging the potential of synthetic data, researchers and developers can overcome the limitations of real-world data, such as scarcity, bias, and privacy concerns.
Quality-diversity generative sampling is a sophisticated technique that combines the strengths of diversity and quality in generating synthetic data. This approach focuses on producing a wide range of data samples that cover multiple variations and characteristics, thereby improving the robustness of AI models. By ensuring that the synthetic data maintains a high-quality standard, it becomes possible to mimic real-world scenarios more accurately. This technique is pivotal in areas such as autonomous driving, healthcare, and robotics, where diverse and high-quality data is crucial for model success.
As we delve into this comprehensive guide, we will explore the various facets of quality-diversity generative sampling for learning with synthetic data. From understanding the fundamental principles to examining practical applications and challenges, this article aims to provide valuable insights into this innovative method. Whether you are a researcher, developer, or enthusiast, the concepts and strategies discussed herein will equip you with the knowledge needed to harness the full potential of synthetic data in your projects.
Read also:Expert Insights Into Hiring An Irs Tax Professional For Stressfree Tax Compliance
Table of Contents
- What Is Synthetic Data?
- Importance of Synthetic Data in AI
- Understanding Quality-Diversity Generative Sampling
- How Does Quality-Diversity Generative Sampling Work?
- Applications of Quality-Diversity Generative Sampling
- Advantages of Using Synthetic Data
- Challenges in Synthetic Data Generation
- Role of AI in Synthetic Data Generation
- Best Practices for Quality-Diversity Generative Sampling
- Ethical Considerations
- The Future of Quality-Diversity Generative Sampling
- How to Start with Quality-Diversity Generative Sampling?
- Key Technologies Driving Synthetic Data
- Frequently Asked Questions
- Conclusion
What Is Synthetic Data?
Synthetic data is artificially generated information that mimics real-world data. Unlike real data, which is collected from actual events or phenomena, synthetic data is created using algorithms and models. It is designed to replicate the statistical properties of real data, making it an invaluable resource for training machine learning models. The creation of synthetic data involves generating samples that are similar in nature to real data but without direct correlation to specific real-world instances.
In the context of machine learning, synthetic data serves multiple purposes. It can be used to augment existing datasets, providing more comprehensive training material for AI models. Moreover, it allows for the simulation of scenarios that are rare or difficult to capture in real life. This capability is crucial for developing robust models that can perform well under various conditions and constraints.
Importance of Synthetic Data in AI
The role of synthetic data in AI cannot be overstated. It addresses several key challenges associated with traditional data collection and utilization. For instance, real-world data may be subject to privacy concerns, regulatory restrictions, or simply be unavailable or insufficient. Synthetic data bypasses these issues by allowing researchers to generate large volumes of data without compromising privacy or breaching regulations.
Additionally, synthetic data enhances the diversity of training datasets, reducing biases that may be present in real-world data. By incorporating a wider range of scenarios and variations, synthetic data helps in creating more generalized models that are less prone to overfitting. This means AI systems trained on synthetic data are likely to perform better when exposed to new and unseen data in real-world applications.
Understanding Quality-Diversity Generative Sampling
Quality-diversity generative sampling is a method used to create synthetic data that is not only diverse but also maintains a certain standard of quality. This approach is valuable for generating datasets that encompass a wide range of possible scenarios and outcomes, which is essential for training robust machine learning models. The technique involves using generative models, such as Generative Adversarial Networks (GANs) or Variational Autoencoders (VAEs), to produce data that is both varied and high in quality.
By focusing on both quality and diversity, this sampling technique ensures that the synthetic data covers multiple aspects and variations of the target domain. This comprehensive coverage is critical for capturing the complexities of real-world situations. Moreover, maintaining quality ensures that the generated data is realistic and useful for model training, preventing the introduction of artifacts or irrelevant information that could degrade model performance.
Read also:Cal Ranch Near Me Your Ultimate Guide To Ranch Life Essentials
How Does Quality-Diversity Generative Sampling Work?
Quality-diversity generative sampling works by employing algorithms that balance the generation of diverse data samples with the upkeep of high-quality standards. This process typically involves several stages, starting with the selection of a generative model. Popular choices include GANs and VAEs, both of which are capable of producing complex, high-dimensional data.
Once a model is chosen, it is trained on existing data to learn the underlying patterns and features. During the training phase, the model iteratively generates new samples, which are then evaluated for both quality and diversity. This evaluation process may involve metrics such as coverage, novelty, and fidelity to ensure that the generated data is both varied and realistic.
Applications of Quality-Diversity Generative Sampling
The applications of quality-diversity generative sampling are vast and varied, spanning numerous fields and industries. In autonomous driving, synthetic data is used to simulate different driving conditions and scenarios, allowing for comprehensive testing and training of self-driving algorithms. This ensures that autonomous vehicles can handle a wide range of situations safely and effectively.
In healthcare, synthetic data plays a crucial role in developing diagnostic models and treatment plans. By providing diverse and high-quality datasets, researchers can create AI systems capable of identifying diseases and recommending interventions with greater accuracy. Furthermore, synthetic data helps in preserving patient privacy, as it does not contain identifiable information.
Advantages of Using Synthetic Data
There are numerous advantages to using synthetic data in machine learning and AI development. Firstly, it provides an abundant source of data that can be tailored to specific needs and requirements. This flexibility allows researchers to generate data that matches the precise criteria of their projects, enhancing the effectiveness of their models.
Synthetic data also offers the benefit of reducing biases commonly found in real-world datasets. By deliberately incorporating a wide range of scenarios and variables, synthetic data can help create models that are more generalized and less likely to overfit. This leads to better performance when deploying AI systems in real-world environments.
Challenges in Synthetic Data Generation
Despite its advantages, generating synthetic data is not without challenges. One of the primary concerns is ensuring that the data is realistic and representative of real-world conditions. If the synthetic data fails to accurately mimic real data, the model trained on it may not perform well when exposed to actual scenarios.
Another challenge is maintaining diversity while avoiding the introduction of artifacts or irrelevant information that can negatively impact model performance. Balancing these aspects requires careful design and evaluation of generative models, as well as the implementation of robust quality control measures.
Role of AI in Synthetic Data Generation
Artificial intelligence plays a central role in the generation of synthetic data. AI algorithms, particularly generative models, are responsible for creating data samples that are diverse and high in quality. These models learn from existing data to understand the underlying patterns and features, which they then use to generate new, synthetic data.
The use of AI in synthetic data generation allows for the creation of complex data that accurately reflects real-world conditions. This capability is essential for training machine learning models that are robust and effective in a variety of applications.
Best Practices for Quality-Diversity Generative Sampling
To maximize the effectiveness of quality-diversity generative sampling, it is important to follow certain best practices. Firstly, the choice of generative model should be based on the specific requirements and constraints of the project. Models such as GANs and VAEs are popular choices due to their ability to produce high-quality, diverse data.
Another best practice is to implement robust evaluation metrics to assess the quality and diversity of the generated data. These metrics should be used throughout the generation process to ensure that the synthetic data meets the necessary standards and is suitable for model training.
Ethical Considerations
While synthetic data offers numerous benefits, it also raises important ethical considerations. One of the key concerns is the potential for misuse, particularly in areas such as surveillance and privacy. It is essential to establish clear guidelines and regulations to govern the use of synthetic data, ensuring that it is used responsibly and ethically.
Additionally, the use of synthetic data should be transparent, with clear documentation of the generation process and the algorithms used. This transparency helps to build trust in the data and the models trained on it, ensuring that stakeholders are aware of any limitations or biases that may be present.
The Future of Quality-Diversity Generative Sampling
The future of quality-diversity generative sampling is promising, with ongoing advancements in AI and machine learning driving the development of more sophisticated generative models. These advancements will enable the creation of even more realistic and diverse synthetic data, further enhancing the capabilities of AI systems.
As the demand for high-quality, diverse data continues to grow, quality-diversity generative sampling will play an increasingly important role in AI development. Its ability to overcome the limitations of real-world data makes it an invaluable tool for researchers and developers across various industries.
How to Start with Quality-Diversity Generative Sampling?
For those interested in implementing quality-diversity generative sampling, the first step is to gain a solid understanding of the underlying principles and techniques. This involves studying the various generative models available and selecting the one that best suits the specific needs of your project.
Once you have chosen a model, the next step is to gather and prepare the data required for training. This data should be representative of the scenarios and conditions you wish to simulate, ensuring that the synthetic data generated is both realistic and diverse.
Key Technologies Driving Synthetic Data
Several key technologies drive the generation of synthetic data, with advances in AI and machine learning playing a pivotal role. Generative models such as GANs and VAEs are at the forefront of this field, enabling the creation of complex, high-dimensional data that closely mimics real-world conditions.
Additionally, advancements in computing power and algorithms have made it possible to generate synthetic data at scale, providing researchers and developers with the resources needed to train and test their models effectively.
Frequently Asked Questions
What is the primary benefit of synthetic data?
Synthetic data provides a scalable and flexible source of data that can be tailored to specific needs, enhancing model training and performance.
How does quality-diversity generative sampling improve AI models?
By generating diverse and high-quality synthetic data, this approach helps create more generalized models that perform well under various conditions.
Can synthetic data replace real-world data completely?
While synthetic data offers many advantages, it is not a complete replacement for real-world data. It should be used in conjunction with real data to provide a comprehensive training dataset.
What are the ethical concerns associated with synthetic data?
Key ethical concerns include privacy, potential misuse, and the need for transparency in the data generation process.
Which industries benefit the most from synthetic data?
Industries such as autonomous driving, healthcare, and robotics benefit greatly from synthetic data due to the need for diverse and high-quality datasets.
How can I ensure the quality of generated synthetic data?
Implementing robust evaluation metrics and quality control measures throughout the data generation process can help ensure the quality of synthetic data.
Conclusion
Quality-diversity generative sampling for learning with synthetic data is a transformative approach that addresses many of the challenges associated with traditional data collection and utilization. By providing diverse and high-quality datasets, this method enhances the development of robust AI models capable of performing well in real-world scenarios. As technology continues to advance, the potential of synthetic data will only grow, offering exciting opportunities for researchers and developers across various industries. Embracing this innovative approach will be key to unlocking the full potential of AI in the years to come.